
這篇文章在講什麼?簡單來說,黃醫師在開發 ACHEOFF 醫療設備軟體時,遇到了一個問題:AI 輔助工具要花錢,但免費額度用完就沒了。於是我參考了網路上的方法——讓 AI 自動在「免費」和「花錢」之間切換,就像手機訊號不好時會自動切換網路一樣。
在開發 ACHEOFF 醫療設備軟體時,需要 AI 幫忙寫程式碼。一開始使用 MiniMax M2.5(很強的 AI 模型),但免費額度用完後就不能用了。
大多數人的選擇:
- 付費繼續使用(但金額會累積)
- 改用免費但較弱的 AI(但速度慢、能力有限)
不想多花錢的黃醫師選擇第三條路:兩個都要!
🛠️ 硬體設備
| 配備 | 規格 |
|---|---|
| 電腦 | Mac Mini M4(2024 年版本) |
| 記憶體 | 16GB 統一記憶體 |
| 系統 | macOS 15+ |
一台普通的 Mac Mini,不是特別貴的那種。
💡 核心概念:「本地優先,雲端補位」
想像你在開車出遊:
- 油箱滿的時候(雲端額度夠)→ 開快一點,用更強的 AI
- 油快用完的時候(雲端額度不足)→ 切換到省油模式,用本地端的 AI
- 本地端 AI 就像「自行車」,隨時可用但速度慢一點
- 雲端 AI 就像「跑車」,很快但需要花錢加油
🔧 系統設定說明(白話版)
1. 在家裡放一個「AI 服務生」
黃醫師在 Mac Mini 裡安裝了一個叫做 oMLX 的軟體,這個軟體專門用來「跑」AI 模型。
因為電腦只有 16GB 記憶體(RAM),所以選擇了一個比較「輕量」的模型叫做 Qwen3.5-9B,這個模型大約佔用 5.82GB 的記憶體,還剩空間給其他程式用。
2. 設定「自動切換開關」
寫了一個小小的程式(叫做 auto_switch.sh),每當 MiniMax 雲端的額度低於 20 次時,系統就會自動切換:
等到下個月額度重置後,又會自動切回 MiniMax M2.5。
3. 讓手機通知他
還設定了 Telegram 機器人,每當 AI 切換模式的時候,手機會收到通知,就像這樣:
🔄 會話啟動!目前使用:Qwen3.5-9B,內容使用率:97%📊 效果如何?
| 之前 | 之後 |
|---|---|
| 用另一個類似軟體(ollama)跑同樣的查詢 | 23 分鐘 |
| 用 oMLX + Qwen3.5 | 幾秒鐘就完成 |
速度提升超級多! 從 23 分鐘變成幾秒鐘,這是因為 oMLX 這個軟體特別優化過,能更有效地利用 Mac Mini 的硬體。
🎁 這樣做有什麼好處?
-
- 省錢:免費額度用完後,自動切到本地端 AI,不用花冤枉錢
-
- 不停工:AI 額度用完不會突然就不能用,系統會無縫切換
-
- 速度快:本地端 AI 反應比雲端快(不用等網路傳輸)
-
- 隱私安全:某些程式碼可以完全在本地端處理,不會傳到網路上
🔑 總結
這方法結合了「雲端 AI」(厲害但要花錢)和「本地 AI」(較弱但免費),並寫了一個自動切換系統,讓我們在開發軟體時既能用到最強的 AI,又不會因為額度用完而中斷工作。
啟發是:如果你的工作需要用到 AI 程式輔助,可以參考這個概念——不要把所有雞蛋放在同一個籃子裡,免費的和付費的搭配使用,才能兼顧效能和成本。
這就是這篇技術文章的通俗解說版本,希望對你有幫助!
下面是技術性較高的正文 (其實黃醫師也不全瞭解—拜Vibe Coding所賜😅)
為了在進行 ACHEOFF 醫療設備開發時擁有高效且不間斷的 AI 輔助,我設計了一套「本地優先,雲端補位」的系統。當 MiniMax 雲端額度充足時,利用其強大的推理能力;當額度用罄或需離線處理時,自動切換至優化過的本地 Qwen3.5 模型。
混合 AI 算力架構:在 Mac Mini M4 上整合 oMLX 與 MiniMax
為了在進行 ACHEOFF 醫療設備開發時擁有高效且不間斷的 AI 輔助,我設計了一套「本地優先,雲端補位」的系統。當 MiniMax 雲端額度充足時,利用其強大的推理能力;當額度用罄或需離線處理時,自動切換至優化過的本地 Qwen3.5 模型。
機型:Mac Mini M4 (2024)
記憶體:16GB 統一記憶體 (Unified Memory)
系統:macOS 15+
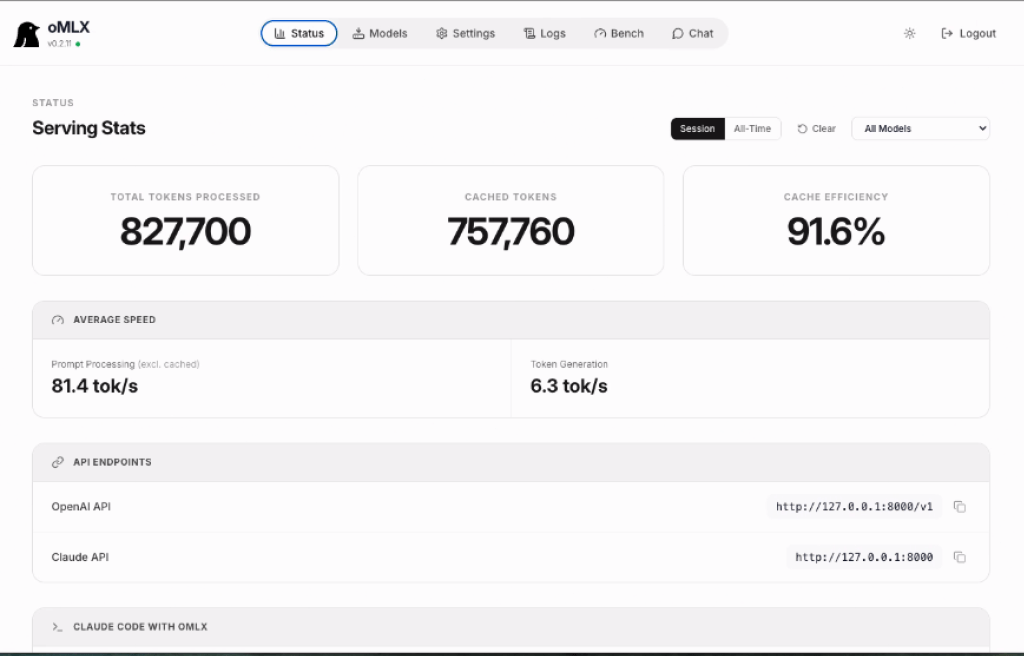
一、 本地端配置:oMLX 與 Qwen3.5 9B
參考了 freedidi.com 的部署建議,針對 16GB RAM 的限制,我選擇了 4-bit 量化的 Qwen3.5-9B-MLX。透過 oMLX 伺服器,我們能精準控制記憶體邊界並啟用高效快取。
oMLX 關鍵設定
{
"max_memory": "11.52GB", // 預留空間給系統與其他應用
"hot_cache_max_size": "8.00GB", // 提升 KV Cache 回應速度
"max_context_window": 32768, // 兼顧深度與記憶體穩定性
"paged_ssd_cache": "Enabled" // 當 RAM 壓力過大時,自動分頁至 SSD
}
這種配置下,Qwen3.5 9B 模型實際佔用約 5.82GB RAM,配合 11.7GB 的程序限制,能確保系統在高負載下依然穩定。
二、 OpenClaw 整合設定
OpenClaw 作為核心調度器,負責連接 oMLX 提供的 OpenAI 相容接口以及 MiniMax 雲端 API。
openclaw.json 配置摘要
{
"models": {
"providers": {
"minimax": {
"baseUrl": "https://api.minimax.io/v1",
"apiKey": "sk-cp-xxxxxxxxxxxx", // 雲端 Coding Plan Key
"models": [{ "id": "MiniMax-M2.5", "contextWindow": 204800 }]
},
"omlx": {
"baseUrl": "http://127.0.0.1:8000/v1",
"apiKey": "local-auth",
"models": [{ "id": "Qwen3.5-9B-MLX-4bit", "contextWindow": 49152 }]
}
}
},
"agents": {
"defaults": { "model": { "primary": "minimax/MiniMax-M2.5" } }
}
}
三、 自動化切換腳本:auto_switch.sh
為了避免 MiniMax Coding Plan 超量導致工作中斷,我撰寫了一個 Bash 腳本,每隔一段時間檢查雲端餘額,並在必要時自動修改 OpenClaw 配置並重啟 Gateway。
#!/bin/bash
# 檢查 MiniMax 餘額並自動切換模型
API_KEY="sk-cp-xxxxxxxxxxxx"
THRESHOLD=20 # 剩餘次數低於此值則切換
# 1. 獲取剩餘額度
BODY=$(curl -s "https://api.minimax.io/v1/api/openplatform/coding_plan/remains" -H "Authorization: Bearer $API_KEY")
REMAINS=$(echo "$BODY" | jq -r '.model_remains[0] | .current_interval_total_count - .current_interval_usage_count')
# 2. 判定邏輯
if [ "$REMAINS" -lt "$THRESHOLD" ]; then
# 切換至本地 oMLX
openclaw config set agents.defaults.model.primary "omlx/Qwen3.5-9B-MLX-4bit"
openclaw gateway restart
else
# 額度充足則保持或換回 MiniMax
openclaw config set agents.defaults.model.primary "minimax/MiniMax-M2.5"
openclaw gateway restart
fi
四、 Telegram 狀態監控:從靜態配置到動態通知
為了確保在 ACHEOFF 開發過程中能即時掌握系統狀態,我實作了兩層級的 Telegram 監控:系統級通訊埠配置與任務級動態狀態回報。
1. 系統級:OpenClaw Channel 配置
首先在 openclaw.json 中啟用原生 Telegram Channel 支援。這允許我直接透過 Telegram 手機端對 Agent 下達指令,同時定義了存取權限 white-list。
"channels": {
"telegram": {
"enabled": true,
"botToken": "873359xxxx:AAFC0rRa...", // 向 @BotFather 申請的憑證
"allowFrom": ["11064xxxxx"], // 限制僅限我的 Chat ID 存取
"streaming": "partial"
}
}
2. 邏輯級:自動切換通知 (Shell Integration)
我在 auto_switch.sh 腳本中整合了 Telegram Bot API。當系統偵測到 MiniMax 額度低於門檻並觸發切換至本地 oMLX/Qwen3.5 時,會同步發送 Push Notification。
# 在 auto_switch.sh 中加入的通知邏輯
if [[ "$CURRENT_MODEL" != *"$LOCAL_MODEL"* ]]; then
# 執行切換...
curl -s -X POST https://api.telegram.org/bot$TG_TOKEN/sendMessage \
-d chat_id=$TG_ID \
-d text="⚠️ MiniMax 額度不足!已自動切換至本地 oMLX 運算。"
fi
3. 任務級:Context 佔用率監測 (Startup Sequence)
針對 Mac Mini M4 16G 的記憶體限制,我設定了 Agent 的「啟動序列 (Startup Sequence)」。每當新建會話(New Session)時,Agent 會自動執行以下工具流:
-
- session_status:調用內部工具獲取目前 Context 佔用百分比(例如:97% used)。
-
- exec (curl):將獲取到的 Token 數據與當前使用的模型名稱(Qwen3.5 9B vs MiniMax M2.5)封裝成 JSON 透過 curl 傳送至手機。
透過這套配置,Agent 在啟動時會主動回報:
"🔄 會話啟動!當前模型: Qwen3.5-9B-MLX, Context: 31.9k/32.8k (97%)"。這讓我能即時判斷是否需要手動下達 /reset 來釋放 KV Cache,避免因記憶體溢出導致的 ACHEOFF 代碼生成中斷。
五、 故障排除與優化
- 目錄權限:修復了 Telegram 插件找不到
telegram.json的ENOENT錯誤,確保了狀態持久化。 - 執行路徑:在
crontab任務中明確定義了export PATH,解決了cron環境下找不到jq的問題。 - 本地端效能:實測顯示 Qwen3.5 9B MLX 在 4-bit 量化下,對 Mac Mini M4 的負載極低,是完美的備援方案。
六、 結語
這套架構完美解決了開發 ACHEOFF 時對強大算力的需求,同時透過 oMLX 的 SSD 分頁技術克服了物理記憶體的不足。透過自動化腳本,我再也不需要手動檢查餘額,能夠專注在代碼與產品開發上。
之前是運用ollama serve qwen3.5:9b, 雖然經過一段時間努力是能跑了,但是回應一個查詢,MiniMax 套餐剩餘多少prompt可用的問題,竟然跑了23分鐘才回答出來😅。這套oMLX可能是在有限記憶體下,運用SSD swap記憶體運用的最有效模式了
👍這套混合算力系統在 2026 年 3 月 16 日正式達成全自動化運作。它不僅讓我們在開發 ACHEOFF 醫療設備時無懼額度限制,更透過本地與雲端的協作,將 Mac Mini M4 的效能壓榨到了極限。這不僅是軟體配置的勝利,更是對自動化維運與資源管理的實踐證明。
報告生成時間:2026-03-16 01:32 (Taipei Time)
